For Human Search · For Agent Calls
面向人类与 AI 的新一代知识基础设施
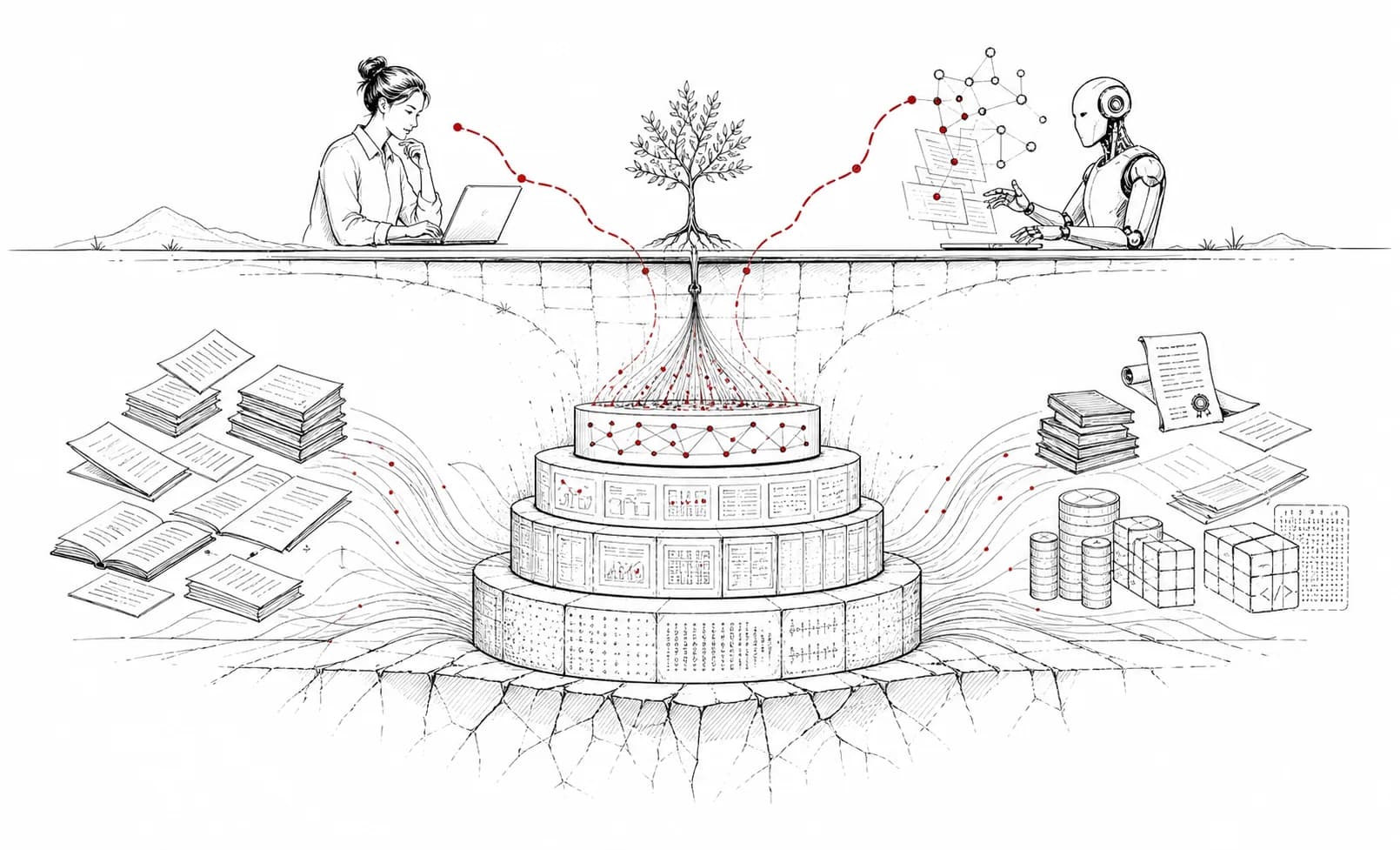
SciBase 覆盖公开学术文献、图书、专利等多类型知识资产,将跨源数据持续加工为可计算、可理解、可追溯、可被 Agent 直接调用的 AI-Ready Knowledge Objects。
01 · Overview
覆盖论文、图书、专利的知识总览
SciBase 不是传统文献检索系统,而是面向大模型时代的 AI-Ready 学术知识基础设施,强调全面性、实时性与 Agent 可用性。

02 · Scenarios
面向人类与 Agent 的核心使用场景
SciBase 的核心价值不只是“检索”,而是作为 Agent 与企业系统的上游知识数据基础设施。
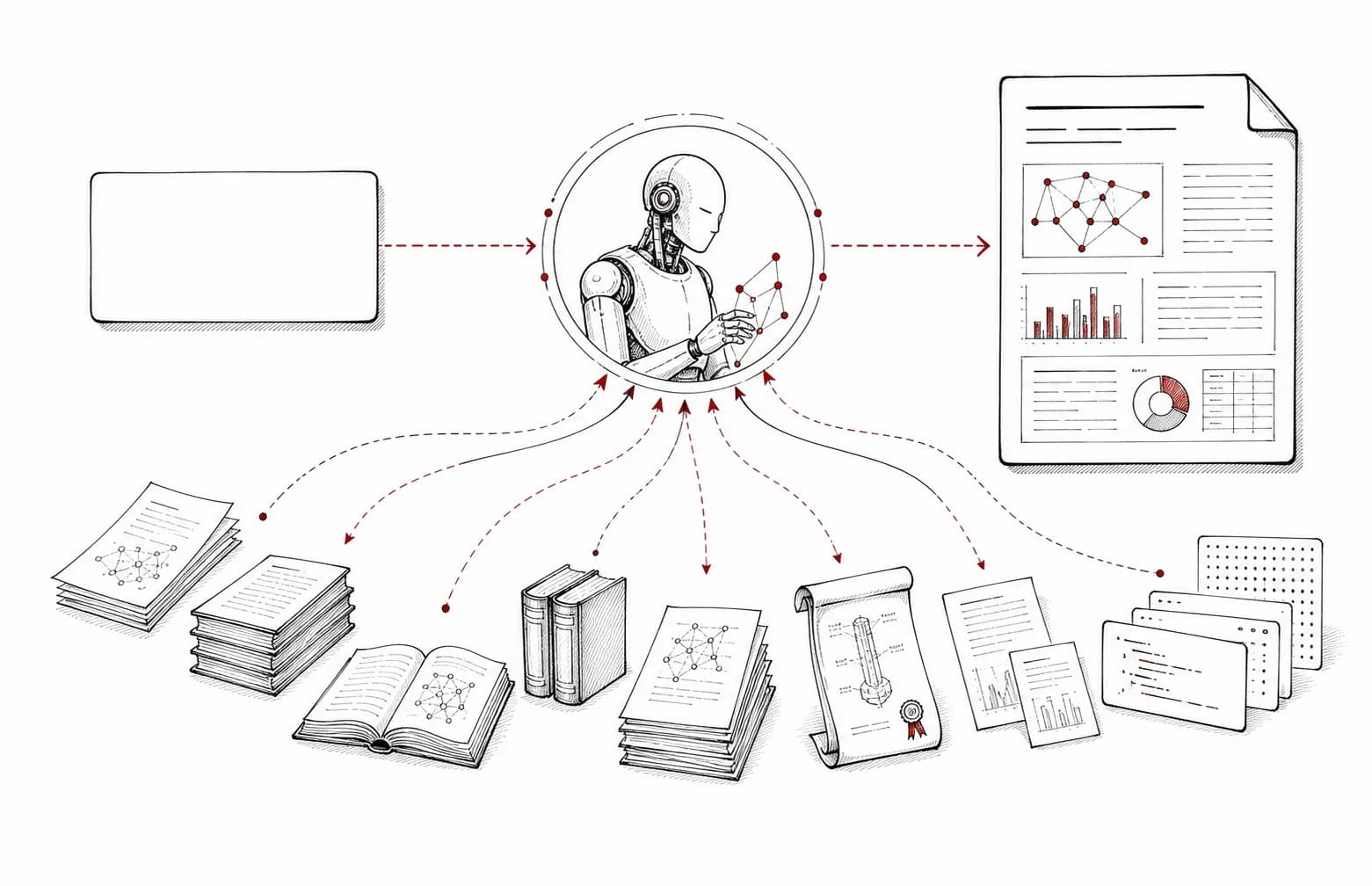
Scenario 01
Research Agent 数据源供给
为 Auto-Research、Deep Research、技术调研 Agent 提供论文、专利、图书、证据片段和引用上下文,支持自动综述和报告生成。
自动文献综述技术路线调研证据包生成
查看场景拆解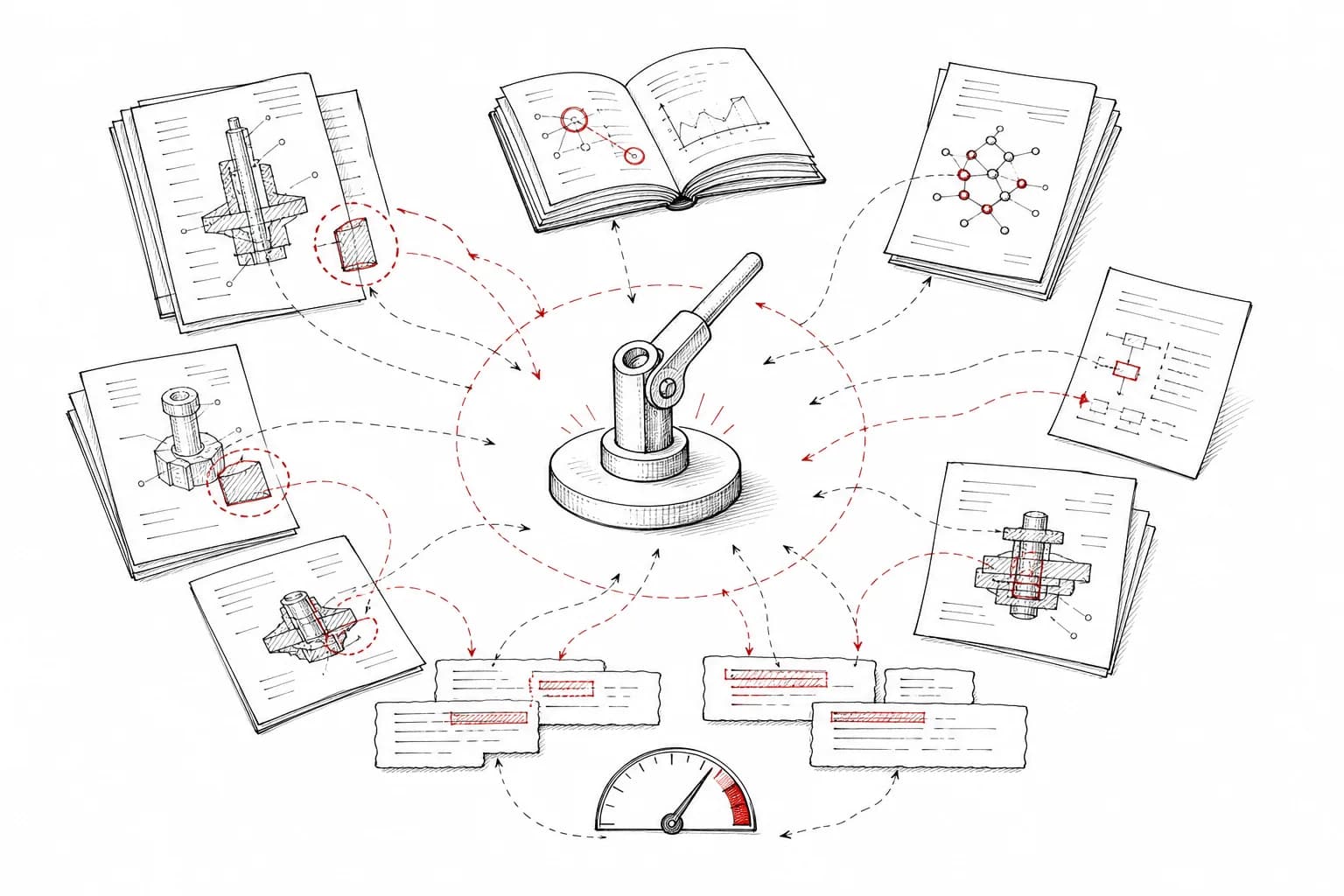
Scenario 02
Prior-Art 与技术查新
围绕一个技术 idea,跨论文、专利、图书和产品资料进行相似技术发现、claim 对比、novelty 风险判断与白区机会分析。
专利查新Novelty 分析论文-专利关联
查看场景拆解
Scenario 03
企业数据挖掘服务
面向 2B 客户提供外部知识 enrichment:将企业项目、研发方向、客户需求与全球论文、专利、作者、机构、公司进行链接。
知识图谱补全技术情报监控机构画像
查看场景拆解03 · Data Foundation Layers
SciBase 数据基座五层架构
从多源接入、原始留存、标准化解析,到知识对象、证据层与索引治理,形成可追溯、可计算、可被 Agent 调用的数据基座。
1多源接入层
接入论文、专利、图书、标准、数据集、代码等多类型来源
2原始数据层
保存原始响应、全文、文件和采集上下文,保证可追溯
3标准化与解析层
统一 schema,解析全文结构,抽取章节、图表、引用和 claims
4知识对象与证据层
生成 Paper、Patent、Book 等 canonical objects 和 evidence spans
5索引治理层
构建全文、向量、图谱、质量、版权和版本索引
04 · Entry
